When you need to show values in a SQL table (RDBMS) with an objective to display values which are duplication, and summarize the same value by count it as a numeric. So, you have to write SQL statement and execute it as an example follow;
Table name “ExamResults”
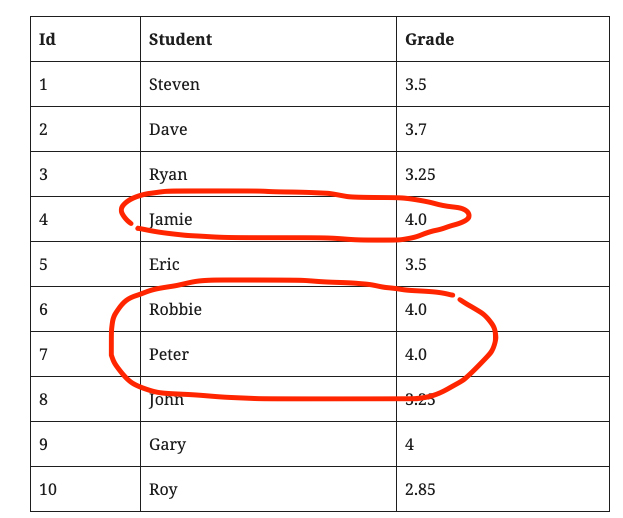
| Id | Student | Grade |
| 1 | Steven | 3.5 |
| 2 | Dave | 3.7 |
| 3 | Ryan | 3.25 |
| 4 | Jamie | 4.0 |
| 5 | Eric | 3.5 |
| 6 | Robbie | 4.0 |
| 7 | Peter | 4.0 |
| 8 | John | 3.25 |
| 9 | Gary | 4 |
| 10 | Roy | 2.85 |
Above table you will see a student with their grade. So, we need to find “how many students who are get grade 4 in the class?”. This question can be responded with our objective to find duplicated values in a table. You have to design your SQL statement using SELECT & GROUP function as follow;
SELECT field_name, COUNT(field_name) AS icount
FROM TABLE_NAME
GROUP BY field_name
to be
SELECT Grade, COUNT(Grade) AS icount
FROM ExamResults
GROUP BY Grade
Result
| Grade | icount |
| 3.5 | 2 |
| 3.7 | 1 |
| 3.25 | 2 |
| 4 | 4 |
| 2.85 | 1 |
This results will tell us how many student each of grades. The number 1 in a column of “icount” is mean to no student in a class which get that grade more than one people, unduplication.
Additional, you can specify to see only a duplicated values in the table by define HAVING function as follow;
SELECT Grade, COUNT(Grade) AS icount
FROM ExamResults
GROUP BY Grade
HAVING COUNT(Grade) > 1
Result
| Grade | icount |
| 3.5 | 2 |
| 3.25 | 2 |
| 4 | 4 |
Moreover, if you need to see the duplicated value under your conditions, you can use WHERE as a condition in your statement as follow;
SELECT Grade, COUNT(Grade) AS icount
FROM ExamResults
WHERE Grade<4
GROUP BY Grade
HAVING COUNT(Grade) > 1
Result
| Grade | icount |
| 3.52 | 2 |
| 3.25 | 2 |
NOTE: SQL statements in this content are fine to execute in MSSQL, but can be applied to use in the other, i.e. MySQL, PostgresQL etc.